
[ad_1]
Machine learning (ML) workloads require efficient infrastructure to yield rapid results. Model training relies heavily on large data sets. Funneling this data from storage to the training cluster is the first step of any ML workflow, which significantly impacts the efficiency of model training.
Data and AI platform engineers have long been concerned with managing data with these questions in mind:
- Data accessibility: How to make training data accessible when data spans multiple sources and data is stored remotely?
- Data pipelining: How to manage data as a pipeline that continuously feeds data into the training workflow without waiting?
- Performance and GPU utilization: How to achieve both low metadata latency and high data throughput to keep the GPUs busy?
This article will discuss a new solution to orchestrating data for end-to-end machine learning pipelines that addresses the above questions. I will outline common challenges and pitfalls, followed by proposing a new technique, data orchestration, to optimize the data pipeline for machine learning.
Common data challenges of model training
An end-to-end machine learning pipeline is a sequence of steps from data pre-processing and cleansing to model training to inference. Training is the most crucial and resource-intensive part of the entire workflow.
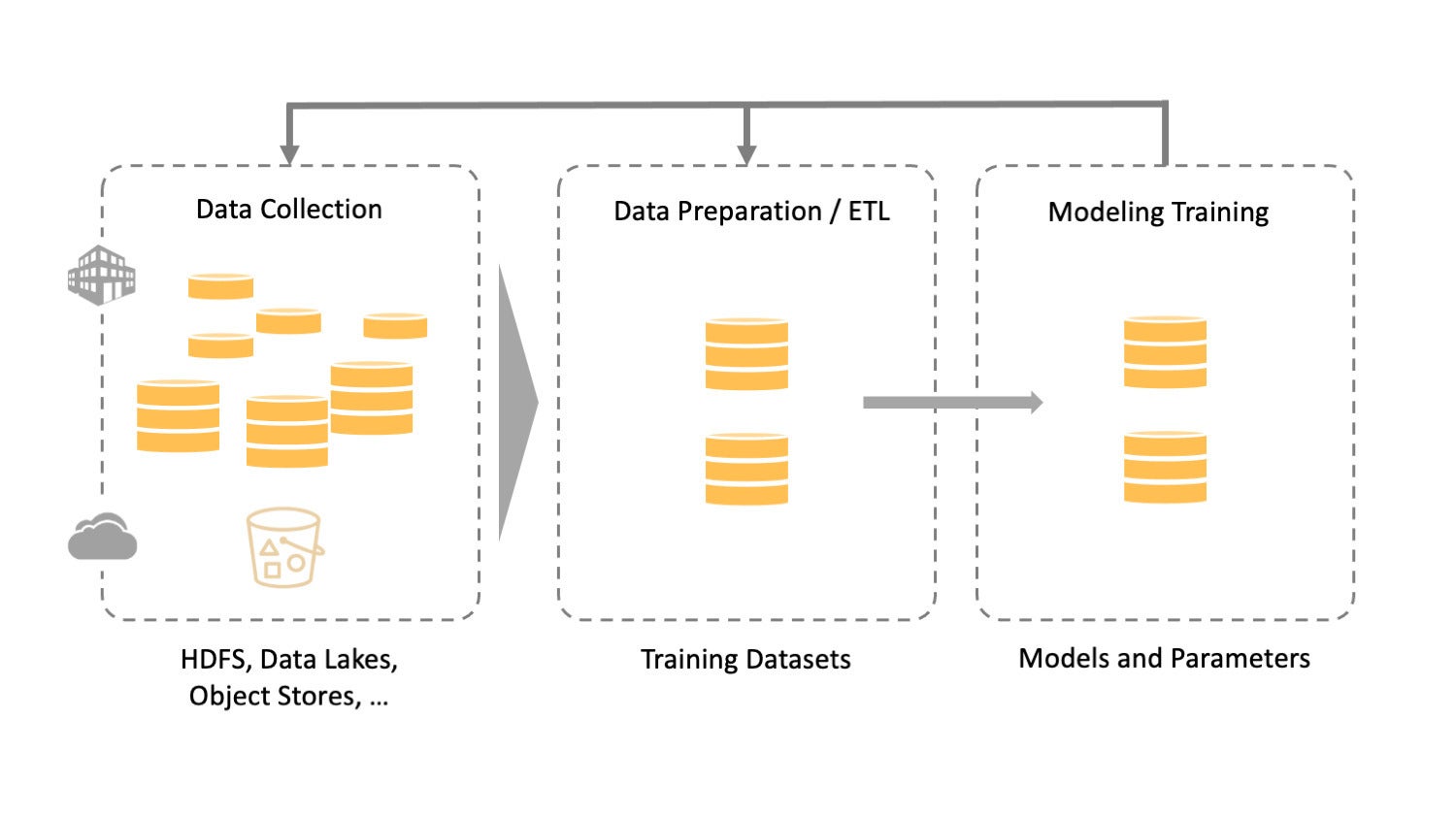
The following diagram shows a typical ML pipeline. It begins with data collection, then comes data preparation, and finally model training. During the data collecting phase, it usually takes data platform engineers a significant amount of time to make the data accessible for data engineers, who to prepare the data for data scientists to build and iterate models.
 Alluxio
AlluxioDuring the training phase, unprecedented volumes of data are processed to ensure the continuous feeding of data to the GPUs that generate models. It is imperative that data be managed to support the complexity of ML and its executable architecture. In the data pipeline, each step presents its own technical challenges.
Data collection challenge – data is everywhere
Training benefits from large datasets, so it’s crucial to collect data from all relevant sources. It is no longer feasible to combine all of the data into a monolithic source when data resides in data lakes, data warehouses, and object stores, whether on-premises, in the cloud, or distributed across multiple geographic locations. With data silos, remote access over the network inevitably causes latency. How to make data accessible while maintaining the desired performance is a significant challenge.
Data preparation challenge – serialized data preparation
Data preparation begins with ingesting data from the collection phase and includes cleansing, ETL, and transformation before delivering data to train the model. If this phase is considered in isolation, the data pipeline is serialized, and extra time is wasted while waiting on data prepared for the training cluster. Therefore, platform engineers must figure out how to create a parallelized data pipeline and enable both efficient data sharing and efficient storage of intermediate results.
Model training challenge – I/O bound with GPU under-utilized
Model training requires processing hundreds of terabytes of data, often massive numbers of small files such as images and audio files. Training involves iterations that require epochs to run multiple times, making frequent access to the data. It is necessary to keep the GPU busy by constantly feeding it with data. It is not easy to optimize I/O and maintain the throughput required by the GPU.
Traditional approaches and common pitfalls
Before I talk about different solutions, let’s set up a simplified scenario, as illustrated in the diagram below. Here, we are training in the cloud using a GPU cluster with multiple nodes running TensorFlow as the ML framework. Pre-processed data is stored in Amazon S3. In general, there are two approaches to getting this data to the training cluster. We’ll discuss those next.
 Alluxio
AlluxioApproach 1: Duplicate data in local storage
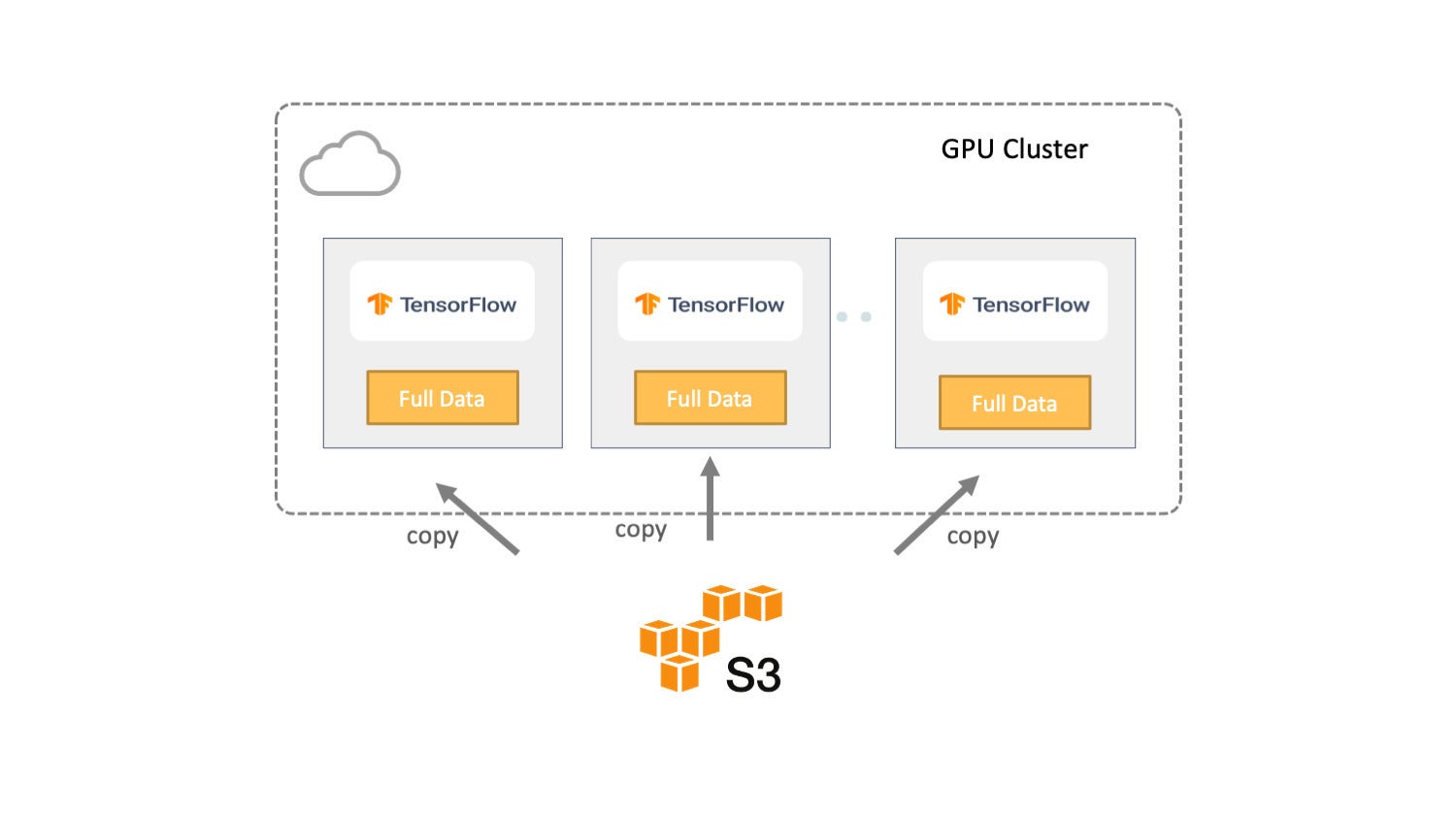
In the first approach, the entire dataset is replicated from the remote storage to the local storage of each server for training, as shown below. Therefore, data locality is guaranteed, and training jobs read the input from local instead of retrieving it from the remote storage.
 Alluxio
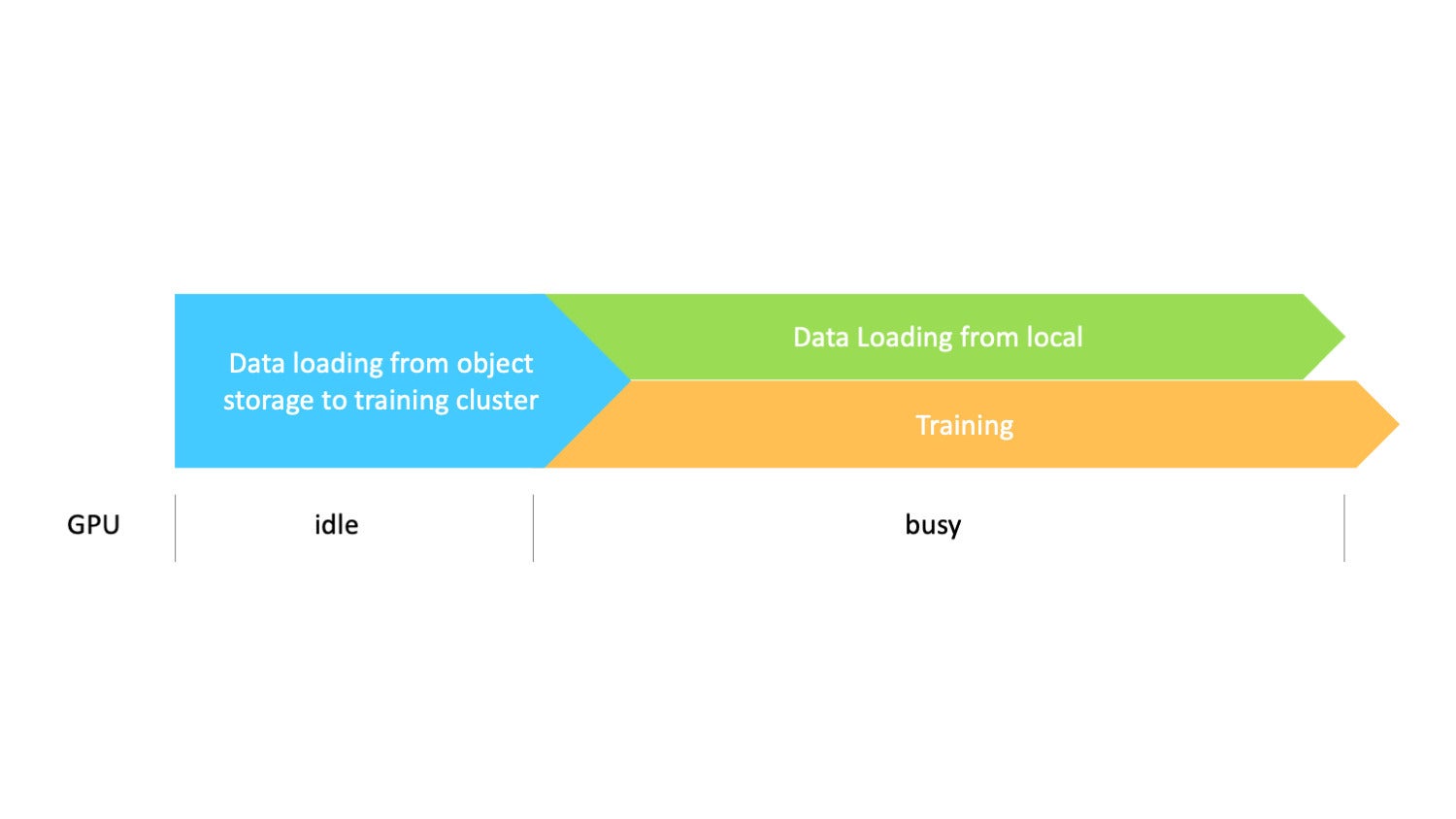
AlluxioFrom the data pipeline and I/O perspective, this approach provides the highest I/O throughput since all data is local. The GPUs will be kept busy except in the beginning since training must wait for data to be entirely copied from object storage to the training cluster.
 Alluxio
AlluxioNevertheless, this approach is not appropriate for all situations.
First, the dataset must fit in the aggregate local storage. As the size of the input dataset grows, the data copy process becomes longer and more error-prone, taking more time with GPU resources wasted.
Second, copying a large amount of data to each training machine creates significant pressure on the storage system and network. In situations where the input data changes often, data synchronization can be very complex.
Lastly, manually making copies of the data is time-consuming and error-prone as it is challenging to keep data on cloud storage synchronized with the training data.
Approach 2: Directly access cloud storage
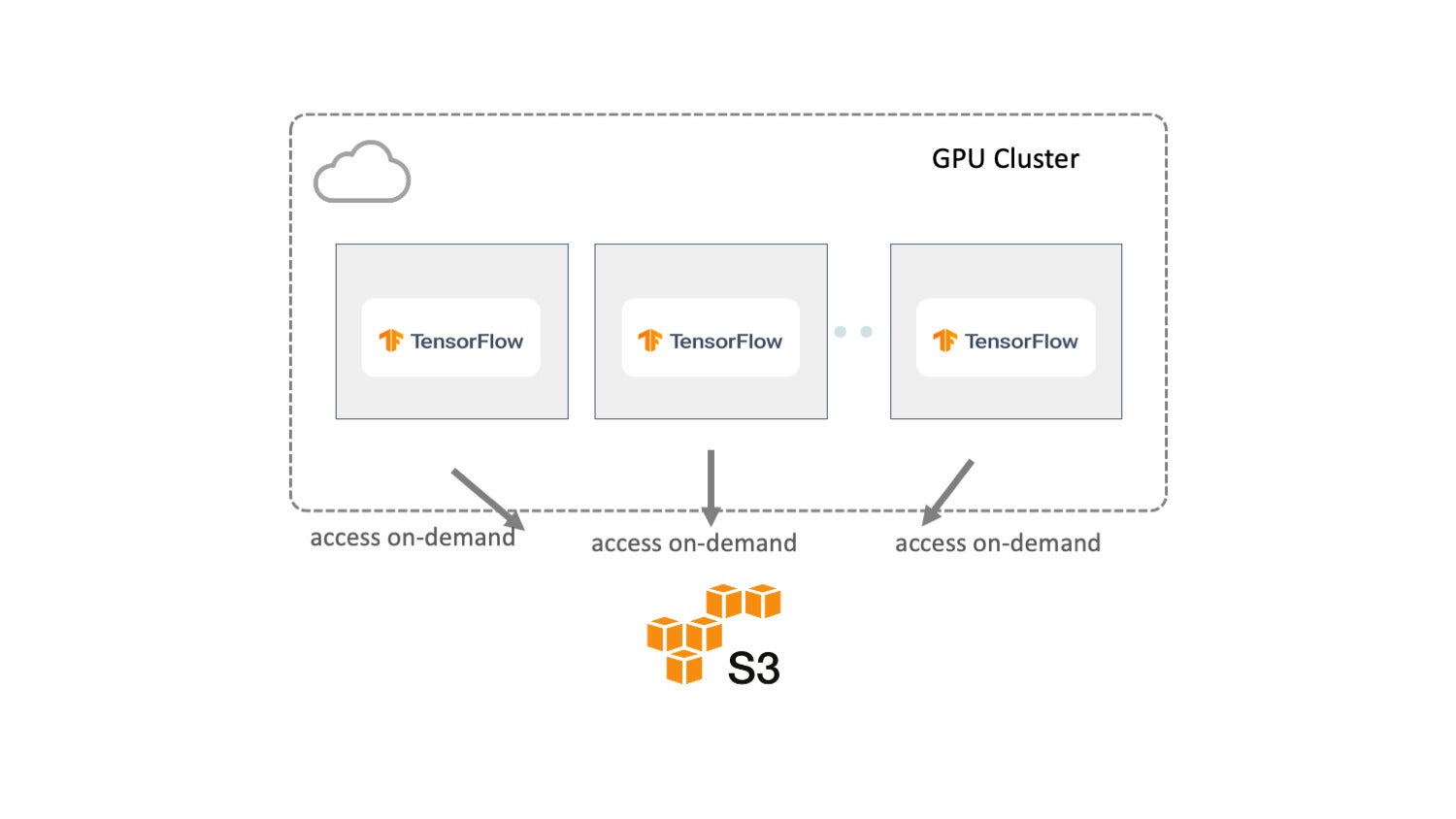
Another common approach is to connect the training with the target dataset on remote storage directly, as shown below. With this approach, the size of the dataset is not an issue, as with the previous solution. But it faces several new challenges.
 Alluxio
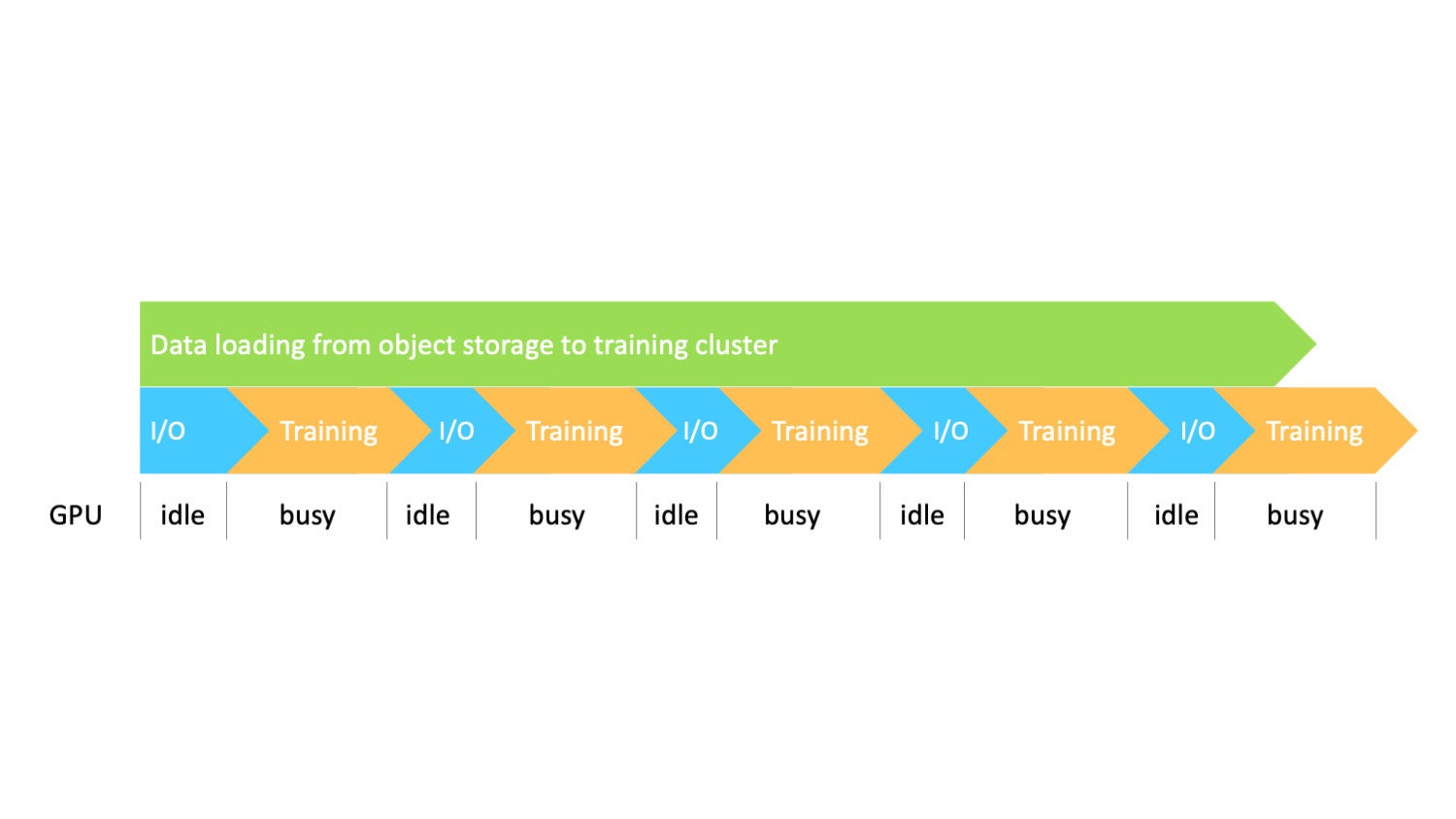
AlluxioFirst, from the I/O and pipeline perspective, data is processed serially. All data access operations must go through the network between object storage and the training cluster, making I/O a bottleneck. As a result, GPUs spend cycles waiting as the I/O throughput is bounded by the network.
 Alluxio
AlluxioSecond, when the training scale is large, all training nodes simultaneously access the same dataset from the same remote storage, adding enormous pressure to the storage system. Storage will likely become congested due to highly concurrent access, resulting in low GPU utilization.
Third, if the dataset consists of a massive number of small files, metadata access requests will account for a large portion of data requests. As a result, directly retrieving the metadata of large numbers of files or directories from the object store becomes the performance bottleneck as well as increases the metadata operation cost.
Recommended approach – orchestrate your data
To address these challenges and pitfalls, we need to re-think the data platform architectures when dealing with I/O in the machine learning pipeline. Here I recommend a new approach, data orchestration, to accelerate the end-to-end ML pipeline. Data orchestration technologies abstract data access across storage systems, virtualize all of the data, and present the data via standardized APIs and a global namespace to data-driven applications.
Unify data silos by using abstraction
Instead of copying and moving data around, leave it where it is, whether it is on-premises or in the cloud. Data orchestration can help abstract the data to create a unified view. This will significantly reduce the complexity in the data collection phase.
Because data orchestration can already integrate with storage systems, machine learning frameworks only need to interact with a single data orchestration platform to access data from any connected storage. As a result, training can be done on all data from any source, leading to improved model quality. There is no need to manually move data to a central source. All computation frameworks, including Spark, Presto, PyTorch, and TensorFlow, can access the data without concern for where it resides.
Use distributed caching for data locality
Instead of duplicating the entire dataset into each single machine, I recommend implementing distributed caching, where data can be evenly distributed across the cluster. Distributed caching is especially advantageous when the training dataset is much larger than a single node’s storage capacity. It also helps when data is remote because data is cached locally. ML training becomes faster and more cost-effective because there is no network I/O when accessing the data.
 Alluxio
AlluxioThe above figure shows an object store where all the training data is stored, and two files to represent the dataset (/path1/file1 and /path2/file2). Rather than storing all of the file blocks on each training machine, the blocks will be distributed across several machines. To prevent data loss and improve read concurrency, each block can be stored on multiple servers simultaneously.
Optimize data sharing across the pipeline
There is a high degree of overlap among data reads and writes performed by an ML training job, both within and across jobs. Data sharing can ensure that all computation frameworks have access to previously cached data for both reading and writing workloads for the next step. For example, if you use Spark for ETL in the data preparation step, data sharing can ensure that the output data is cached and available for future stages. Through data sharing, the entire data pipeline gains better end-to-end performance.
Orchestrate the data pipeline by parallelizing data preloading, caching, and training
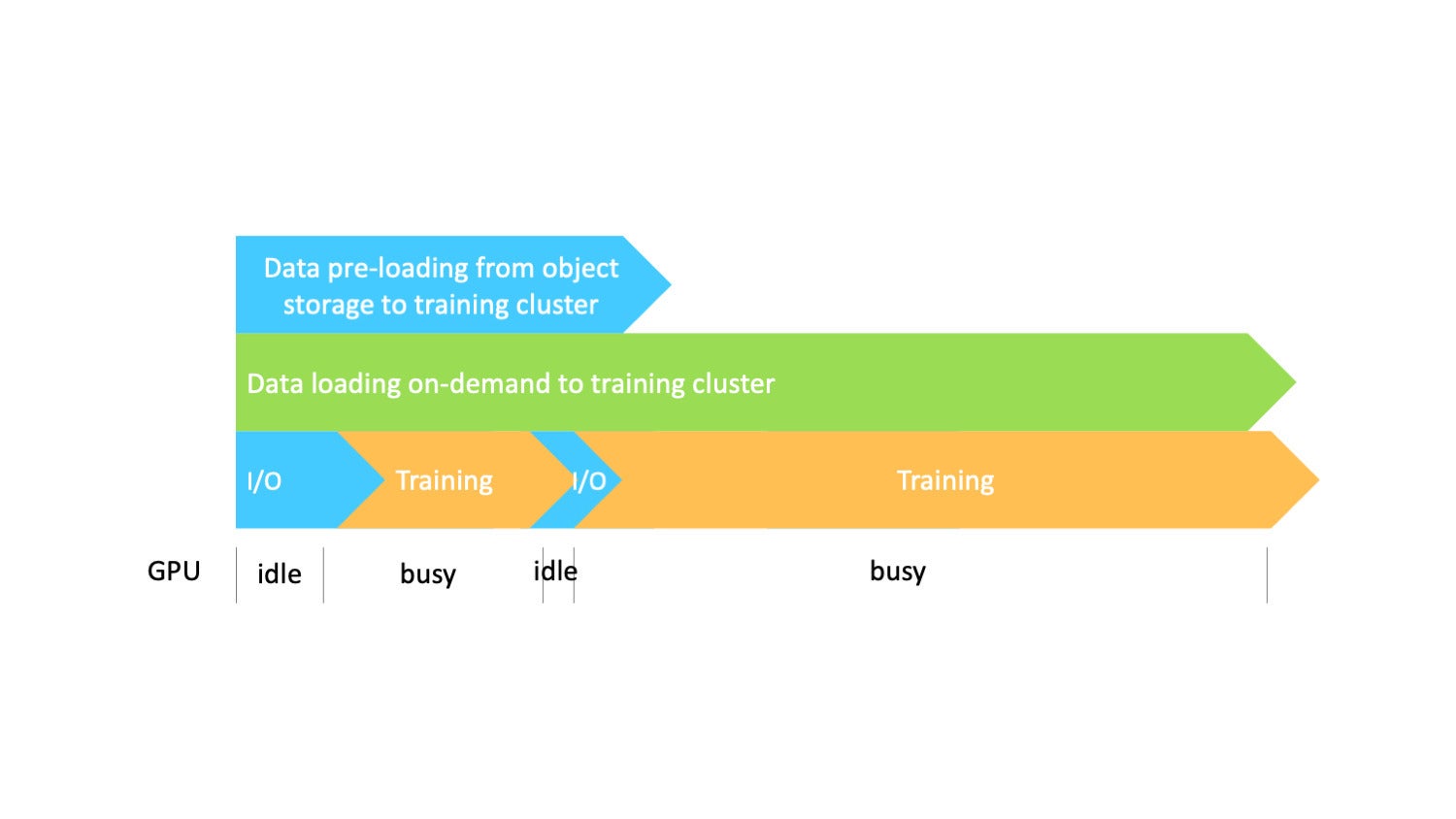
We orchestrate the data pipeline by implementing preloading and on-demand caching. The picture below shows that loading data from the source with data caching can be done in parallel with the actual training task. As a result, training benefits from high data throughput when accessing data without the need to wait to cache the full data before training.
 Alluxio
AlluxioAlthough there will be some I/O latency in the beginning, the wait time will decrease because data is already loaded into the cache. Through this approach, you can overlap the steps. Data loading from object storage to the training cluster, caching, data loading on-demand into the training, and training all can be done in parallel, greatly accelerating the entire process.
Let’s compare the new recommended approach with the two traditional approaches. By orchestrating the data across the steps of a machine learning pipeline, we eliminate serial execution and the associated inefficiencies as data flows from one stage to the next. This in turn will yield a high GPU utilization rate.
|
Duplicate data in local storage |
Directly access cloud storage |
Data orchestration |
|
|
Data locality |
✓ |
✓ |
|
|
No limitation to the size of dataset |
✓ |
✓ |
|
|
No need to copy full data manually before training |
✓ |
✓ |
✓ |
|
Data consistency is ensured |
✓ |
✓ |
|
|
GPU utilization is high |
✓ |
✓ |
How to orchestrate data for your ML workloads
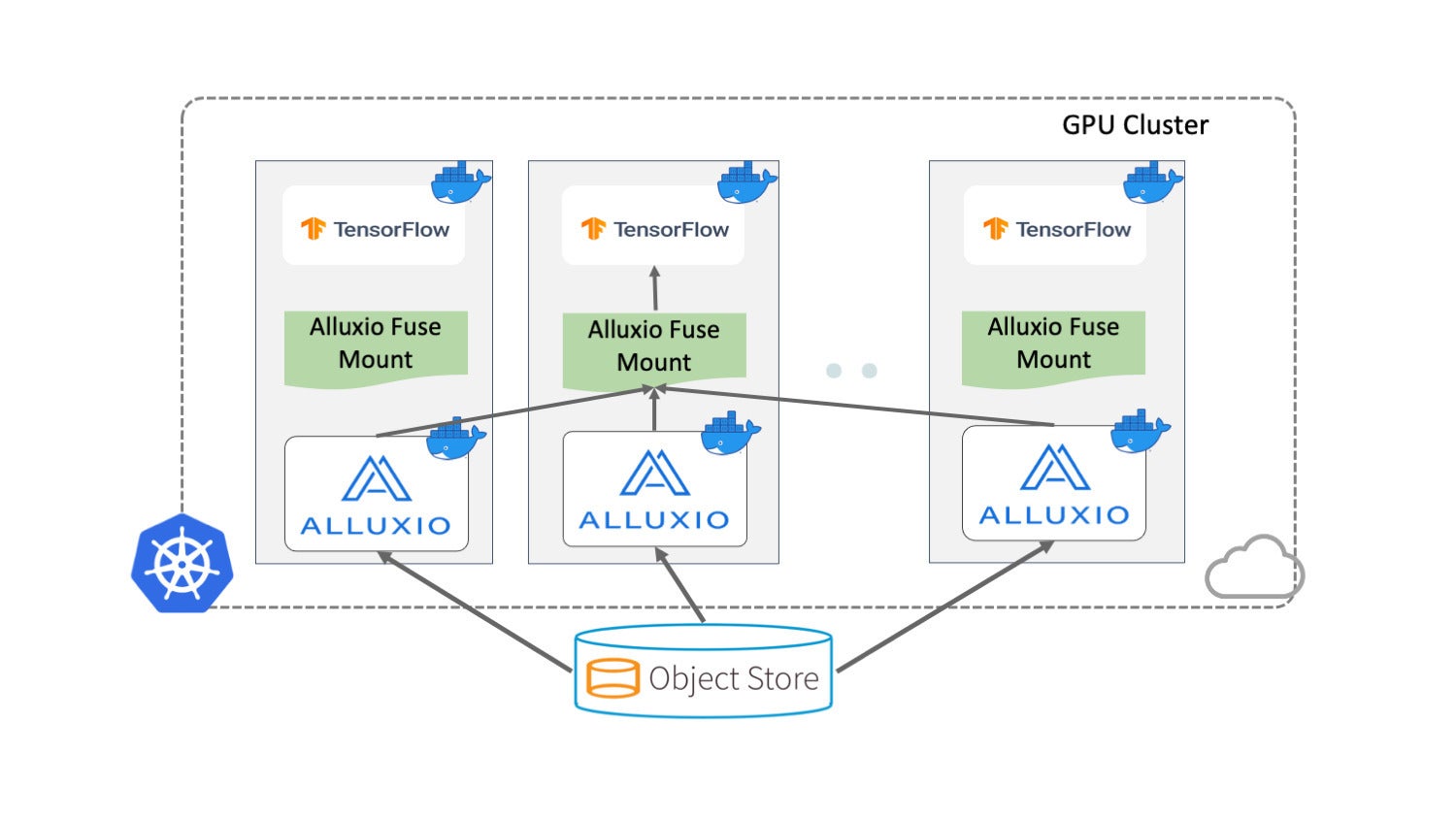
Let’s use Alluxio as an example here to show you how to use data orchestration. Again, we’ll use the same simplified scenario. To schedule TensorFlow jobs, you can either use Kubernetes or use public cloud services.
 Alluxio
AlluxioUsing Alluxio to orchestrate machine learning and deep learning training typically consists of three steps:
- Deploy Alluxio on the training cluster.
- Mount Alluxio as a local folder to training jobs.
- Load data from local folders (backed by Alluxio) using a training script.
Data in different storage systems can be accessed through Alluxio immediately after mounting and they can be transparently accessed through the benchmark scripts without modifying TensorFlow. This significantly simplifies the application development, which otherwise would need the integration of each particular storage system as well as the configurations of the credentials.
You can follow the guide here to run image recognition using Alluxio with TensorFlow.
Data orchestration best practices
Because there is no one-size-fits-all approach, it is best to use data orchestration in the following scenarios:
- You need distributed training.
- There is a large amount of training data (10 TB or more), especially if there are many small files and images in the training data.
- Your GPU resources aren’t sufficiently occupied by the network I/O.
- Your pipeline uses many data sources and multiple training/compute frameworks.
- The underlying storage needs to be stable while you are handling additional training requests.
- The same dataset is used by multiple training nodes or tasks.
As machine learning techniques continue to evolve and the frameworks perform more complex tasks, our methods for managing the data pipeline will also improve. By extending data orchestration to the data pipeline, you can achieve better efficiency and resource utilization for your end-to-end training pipeline.
Bin Fan is VP of open source at Alluxio and the PMC maintainer of Alluxio open source. Prior to joining Alluxio as a founding engineer, he worked for Google to build the next-generation storage infrastructure. Bin received his PhD in computer science from Carnegie Mellon University on the design and implementation of distributed systems.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to [email protected].
Copyright © 2022 IDG Communications, Inc.
[ad_2]
Source link